|
Today recommender systems are the work horse behind every
eCommerce portal - Amazon, Netflix, iTunes, Flipkart, Jabong.
Each of these sell hundreds of thousands of items; they cannot
expect the users to sift through all the items to find what they
like. These portals need to automatically suggest relevant items
to users if they want to keep an edge in the cyber world. The
algorithms that are used for such recommender systems are termed
as Collaborative Filtering.
There are two approaches to this. The first one is simple
and intuitive. The algorithm finds out similar users and items,
and recommends objects based on similarity to the user. The
second approach is mathematically more complex - it is based on
the latent factor model. Here it is assumed that the user's
preference on an item is determined by his / her affinity
towards certain characteristics of the item's possession of
those characteristics. Although abstract, latent factor models
are powerful and yields significant improvement over the simpler
similarity based approach.
Traditionally, the latent factor model was solved using a
matrix factorization approach - which although computationally
efficient, is a non-convex problem. Recently the latent factor
model was further abstracted into a low-rank matrix completion
problem. This leads to a convex formulation but computationally
challenging.
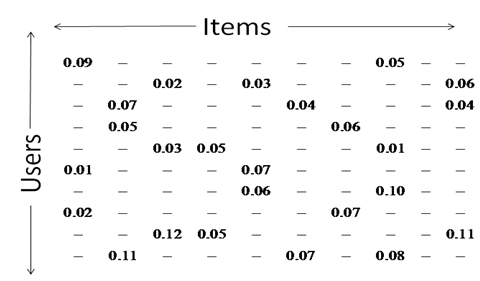
Collaborative filtering requires solving for a partially
sampled choices matrix. On one direction are the users and the
other constitutes the items. Some of the choices are known
(ratings, buying patter, browsing history etc.); if this matrix
is completely known, our problem is solved. Only highly
preferred items will be suggested for each user.
Basically this is an interpolation problem, where the task
is to complete this matrix. This matrix is low-rank - following
from the latent factor model.
At this Lab, we work on various matrix completion
algorithms. How to make these algorithms efficient and
computationally less demanding?
We are also looking at new models for collaborative
filtering where we can incorporate prior knowledge about the
users and items from the available metadata. For example, how to
improve the prediction by using age, occupation, demography or
gender information? How to increase variations in user's choices
while predicting new items?
We are looking for industrial partners in this area.
Please contact us if interested.
|
